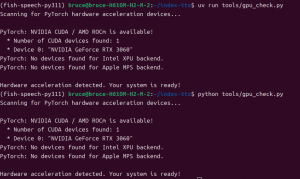
DrissionPage是一个基于Python的网页自动化库,它结合了selenium和requests的优点,可以轻松实现网页的自动化操作。DrissionPage的主要特点是其简洁的API设计,使得用户可以很容易地编写代码来实现网页自动化。
特点
- 简洁的API设计:DrissionPage的API设计非常简洁,用户无需深入了解Selenium的底层实现,也能进行复杂的网页交互。
- 结合了selenium和requests的优点:既可以实现动态网页的自动化,也可以实现静态网页的自动化。
- 灵活性:支持多种选择器,包括CSS选择器、XPath选择器等,适应不同的网页结构。
- 强大的等待机制:内置智能等待,确保元素在操作前已经加载完成。
- 支持多种浏览器:DrissionPage支持多种浏览器,包括Chrome、Firefox等。
安装
安装DrissionPage非常简单,只需要通过pip安装即可:
pip install drissionpage
初始化
在使用DrissionPage之前,需要先进行初始化。可以使用以下代码进行初始化:
from DrissionPage import MixPage
page = MixPage(‘chrome’)
这里我们使用Chrome浏览器进行初始化,你也可以使用其他浏览器,例如Firefox。
打开网页
初始化之后,可以使用open_url方法来打开一个网页。
例如,我们可以使用以下代码来打开百度首页:
page.open_url(‘https://www.baidu.com’)
查找元素
在打开网页之后,我们通常需要查找网页中的元素。DrissionPage提供了多种方法来查找元素,例如ele、eles、css、xpath等。例如,我们可以使用以下代码来查找百度首页的搜索框:
search_box = page.ele(‘#kw’)
这里我们使用ele方法来查找id为kw的元素。
操作元素
在找到元素之后,我们可以对元素进行各种操作,例如输入文本、点击等。例如,我们可以使用以下代码来在百度搜索框中输入文本并搜索:
search_box.send_keys(‘Python’)
page.ele(‘#su’).click()
这里我们使用send_keys方法来输入文本,使用click方法来点击搜索按钮。
获取元素信息
在找到元素之后,我们还可以获取元素的各种信息,例如文本、属性等。例如,我们可以使用以下代码来获取百度搜索结果的第一条结果的标题:
title = page.ele(‘.t a’).text
print(title)
此外,DrissionPage支持复杂的网页交互,例如填写表单、点击按钮等:
# 填写表单
browser.find_element_by_name(‘username’).send_keys(‘my_username’)
browser.find_element_by_name(‘password’).send_keys(‘my_password’)
# 点击登录按钮
browser.find_element_by_xpath(‘//button[@type=”submit”]’).click()
其他示例
DrissionPage可以用于各种网页操作,下面是一些常见的使用示例:
# 处理下拉菜单
browser.find_element_by_id(‘dropdown’).click()
browser.find_element_by_xpath(‘//option[@value=”option-value”]’).click()
# 滚动到页面底部
browser.scroll_to_bottom()
# 获取当前页面的URL
current_url = browser.get_current_url()
# 下拉刷新
page.execute_script(‘window.scrollTo(0, document.body.scrollHeight)’)
# 上传文件
upload_button = page.ele(‘#upload’)
upload_button.send_keys(‘path/to/your/file’)
工作原理
DrissionPage的工作原理非常简单。它首先使用requests库来请求网页,然后使用selenium库来加载网页。在加载网页之后,就可以使用selenium的方法来查找元素、操作元素等。
高级用法
DrissionPage还支持多窗口和多标签页操作、自定义等待、处理JavaScript弹窗等高级功能:
切换到新的标签页
browser.open_new_tab()
自定义等待
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
wait = WebDriverWait(page.driver, 10)
element = wait.until(EC.element_to_be_clickable((By.ID, ‘some_id’)))
这里我们使用selenium的WebDriverWait和expected_conditions来实现自定义等待。
处理JavaScript弹窗
page.driver.switch_to.alert.accept()
这里我们使用switch_to.alert.accept()来处理JavaScript弹窗。
总结
DrissionPage是一个功能强大且易于使用的Python库,它简化了网页自动化操作,使得即使是编程新手也能快速上手。通过本文的介绍,相信你已经对DrissionPage有了基本的了解,并且能够开始使用它来完成你的网络爬虫项目。
附录
- DrissionPage的相关文档:https://gitee.com/g1879/DrissionPage
- selenium官方文档:https://www.selenium.dev/documentation/en/
- requests官方文档:https://requests.readthedocs.io/en/m